-
星空体育登录入口:在NeurIPS 2021上,谷歌改进的Vision Transformer取得了四个显著的SOTA成果,并获得了收录。
- 时间:2024-06-23 来源:zoc7RcITctunhMtq7EzA 人气:
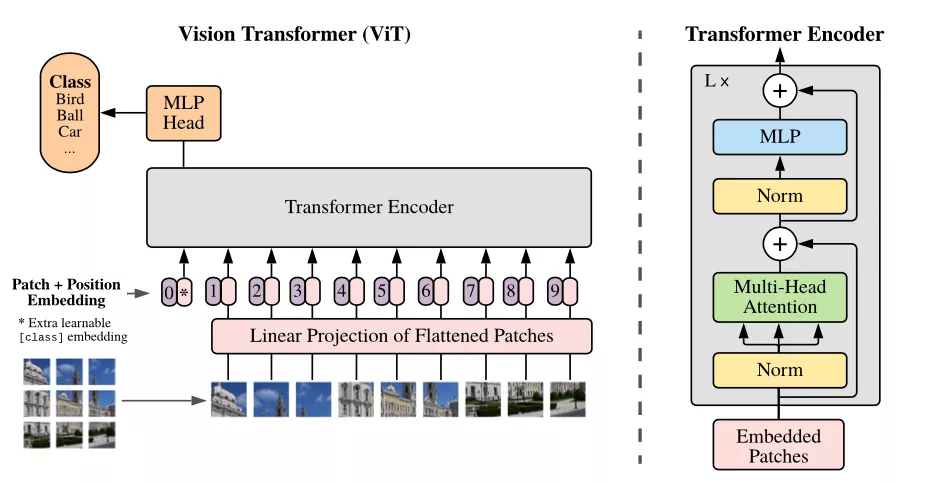
在这篇文章中,谷歌提出了TokenLearner方法,Vision Transformer使用它最多可以减少计算量的8倍,同时提高了分类性能!目前,在计算机视觉任务中,Transformer模型(包括目标检测和视频分类等任务)取得了最领先的成果。与标准的像素卷积方法不同,Vision Transformer(ViT)将图像分解为一系列patch token,即由多个像素组成的小部分图像。这也就意味着在每个神经网络层中,ViT模型运用多头自注意力(multi-head self-attention),根据token之间的关系来处理patch token。通过这种方式,ViT 模型可以生成整个图像的整体表示。在输入时,将图像均匀地切成多个子部分,形成令牌(token)。比如,将512×512像素的图像切割成16×16像素的小块令牌。在中间层,上层的输出被作为下层的令牌。这里插入一句话
。若涉及视频处理,则视频“管道”中的16x16x2视频段(2帧16x16图像)将成为token。Vision Transformer的整体性能取决于视觉token的质量和数量。许多视觉转换器结构都面临一个主要挑战,就是通常需要大量的标记才能得到合理的结果。举例来说,即使使用16x16的图块来进行分词,一个单独的512x512图像也会对应1024个图块。针对拥有多个帧的视频,每一层可能需要处理成千上万个令牌。由于Transformer的计算量随着标记数量的增加而呈二次方增加,因此通常会导致Transformer难以处理更大的图像和更长的视频。
这就带来一个疑问:是否每一层都需要处理这么多的标记呢?谷歌发表了关于“TokenLearner:8个学习令牌在图像和视频中的应用”的研究。在那篇文章中谈到了“自适应”这个概念。本文将在2021年的NeurIPS会议上展示。论文链接:https://arxiv.org/pdf/2106.11297.pdf\n项目链接:https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner\n研究结果显示,TokenLearner可以根据需要生成更少数量的token,而不是仅仅依赖于由图像均匀分配形成的token,这样可以提高Vision Transformer的运行速度和性能。
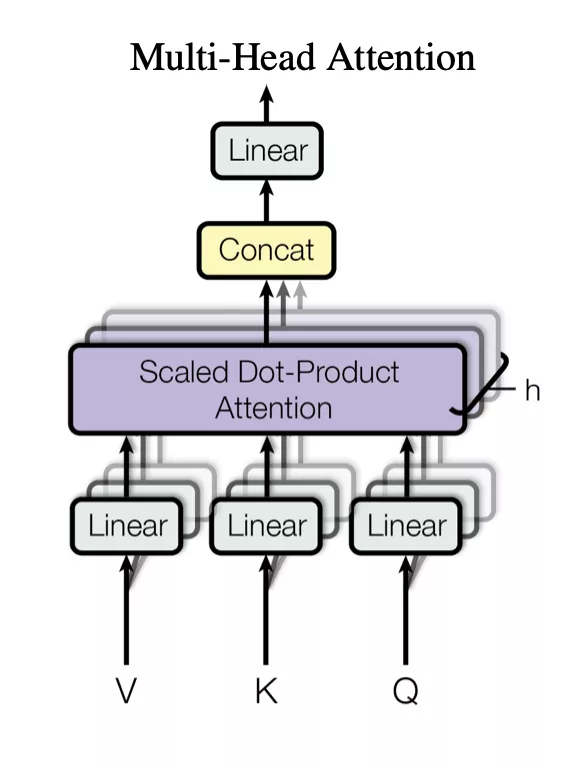
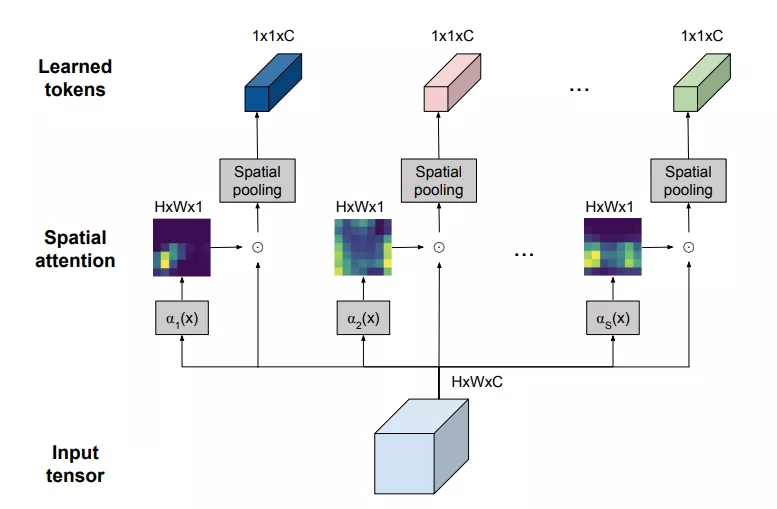
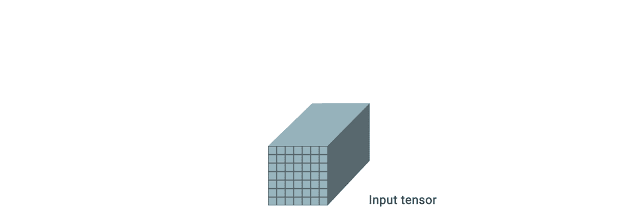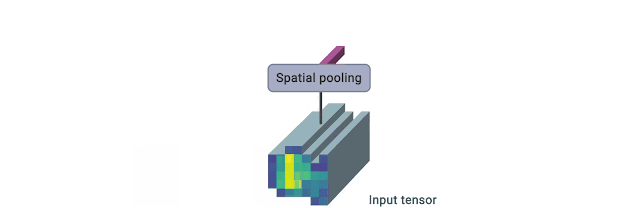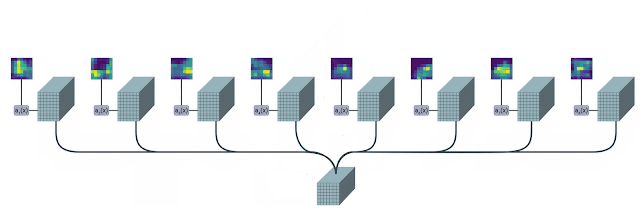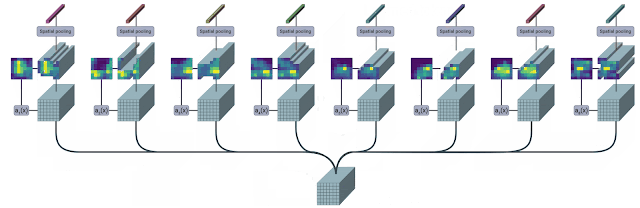
TokenLearner是一个可以学习的模块,它接收图像张量(即输入),然后生成一组token。此模块可放置于Vision Transformer模型的不同位置,显著减少了后续所有层需要处理的标记数量。根据实验结果显示,使用TokenLearner能够减少至少一半的内存和计算量,同时不降低分类性能。由于其适应输入的能力,甚至能够提高准确率。TokenLearner是什么?TokenLearner其实是一种简单的空间注意力技术。为了确保每个TokenLearner学习到有价值的信息,首先需要计算一个突出重要区域的空间注意力图。可以通过使用卷积层或多层感知机(MLP)来实现这一目的。接下来,这种注意力图将用于加权输入中的各个区域(以便排除不必要的区域),然后经过空间池化处理后,就能生成最终经过学习的标记了。TokenLearner模块用直观的图示展示了在单个图像上的应用。TokenLearner通过学习在张量像素的子集上进行空间处理,生成适应输入的一组token向量。通过多次并行重复
 这个操作,就能够从最初的输入中获得n个(大约10个)记号。换另一种说法,可以将TokenLearner视为根据权重值进行像素选择,并随后进行全局平均。值得一提的是,计算注意力图的功能由不同的可学习参数控制,并以端到端的方式进行训练。这样就能够优化注意力机制在捕获不同输入中的空间信息时的功能。在实际操作中,模型会学习多个空间注意力函数,并将它们应用到输入上,同时生成不同的标记向量。TokenLearner模块学习为每个输出标记生成一个空间注意力图,并利用此图来抽象化输入的token。因此,TokenLearner使模型能够处理与特定识别任务相关的少量token,而不是处理固定的、统一的token化输入。TokenLearner启用了自适应token,即根据输入动态选择token,这样有效地减少了token的数量,显著减小了Transformer网络的计算量。
这个操作,就能够从最初的输入中获得n个(大约10个)记号。换另一种说法,可以将TokenLearner视为根据权重值进行像素选择,并随后进行全局平均。值得一提的是,计算注意力图的功能由不同的可学习参数控制,并以端到端的方式进行训练。这样就能够优化注意力机制在捕获不同输入中的空间信息时的功能。在实际操作中,模型会学习多个空间注意力函数,并将它们应用到输入上,同时生成不同的标记向量。TokenLearner模块学习为每个输出标记生成一个空间注意力图,并利用此图来抽象化输入的token。因此,TokenLearner使模型能够处理与特定识别任务相关的少量token,而不是处理固定的、统一的token化输入。TokenLearner启用了自适应token,即根据输入动态选择token,这样有效地减少了token的数量,显著减小了Transformer网络的计算量。这些动态自适应生成的令牌也可以被应用于标准的Transformer结构,比如图像领域的ViT和视频领域的ViViT(视频视觉Transformer)。TokenLearner放在什么地方?在构建TokenLearner模块之后,下一步就是要决定将其放置在哪个位置。
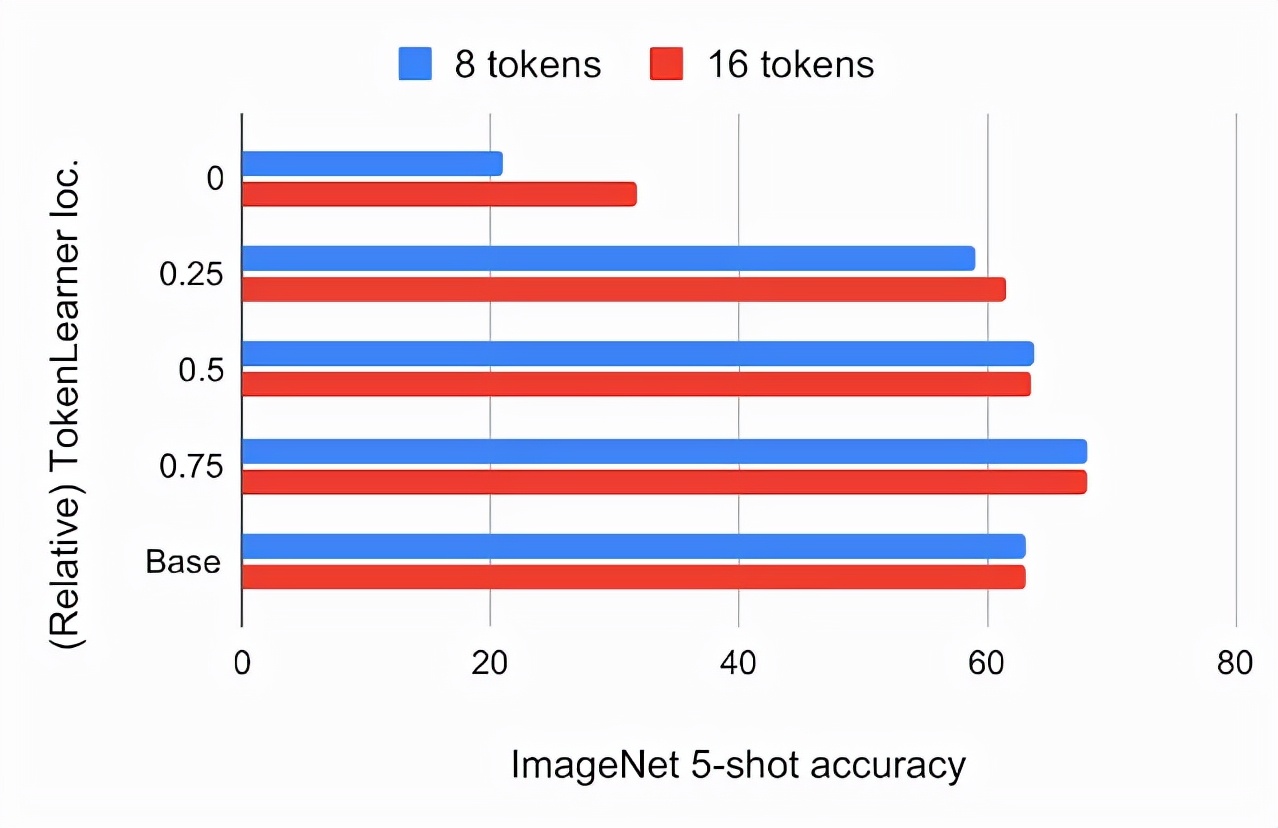
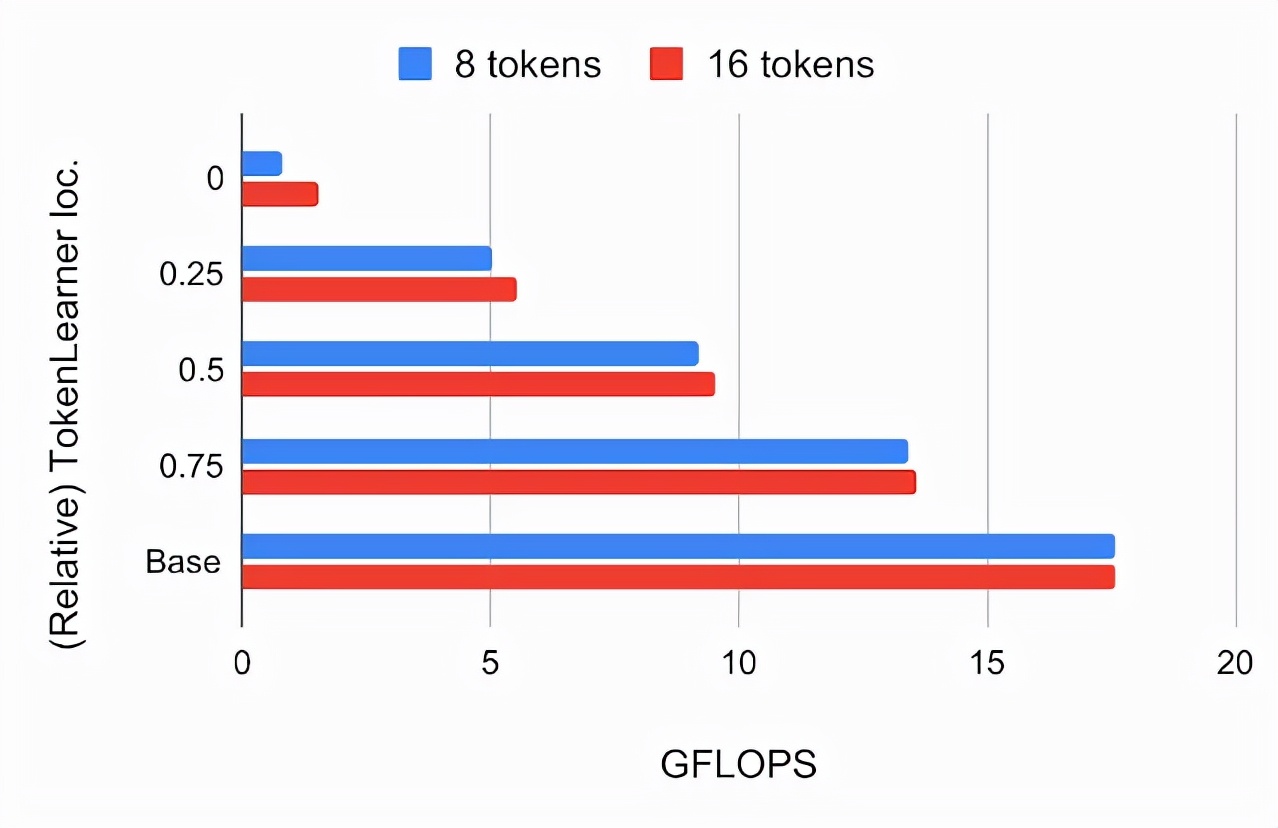
研究者首先尝试将其放置在标准ViT架构的不同位置,将输入图像的大小设置为224x224。TokenLearner生成的token数量分别为8个和16个,远低于标准ViT所使用的196个或576个token。下面的图表展示了将TokenLearner插入ViT B/16模型不同相对位置后,在ImageNet 5-shot分类精度和FLOPs方面的变化。ViT B/16是一个包含12个注意力层的基础模型。它在运行时使用16x16大小的图块标记。在经过JFT 300M的预训练后,ImageNet的5-shot精度与ViT B/16中TokenLearner的相对位置有关。位置0表示TokenLearner被置于任何Transformer层之前。在这里,baseline是根据ViT B/16标准的ImageNet 5-shot分类准确率和FLOPs来设定的。
的计算量以十亿次浮点运算(GFLOPS)来衡量。我们发现,在网络的最初四分之一处(1/4处)插入TokenLearner后,几乎可以达到基线准确度,同时将计算量降低到基线的三分之一以下。此外,将 TokenLearner 放置在较深的层(即网络的 3/4 处),相较于不使用 TokenLearner,表现更出色且适应性更快。由于TokenLearner前后的令牌数量存在很大差异(例如,前196个,后8个),后续TokenLearner模块的相对计算量可以忽略不计。TokenLearner和ViT
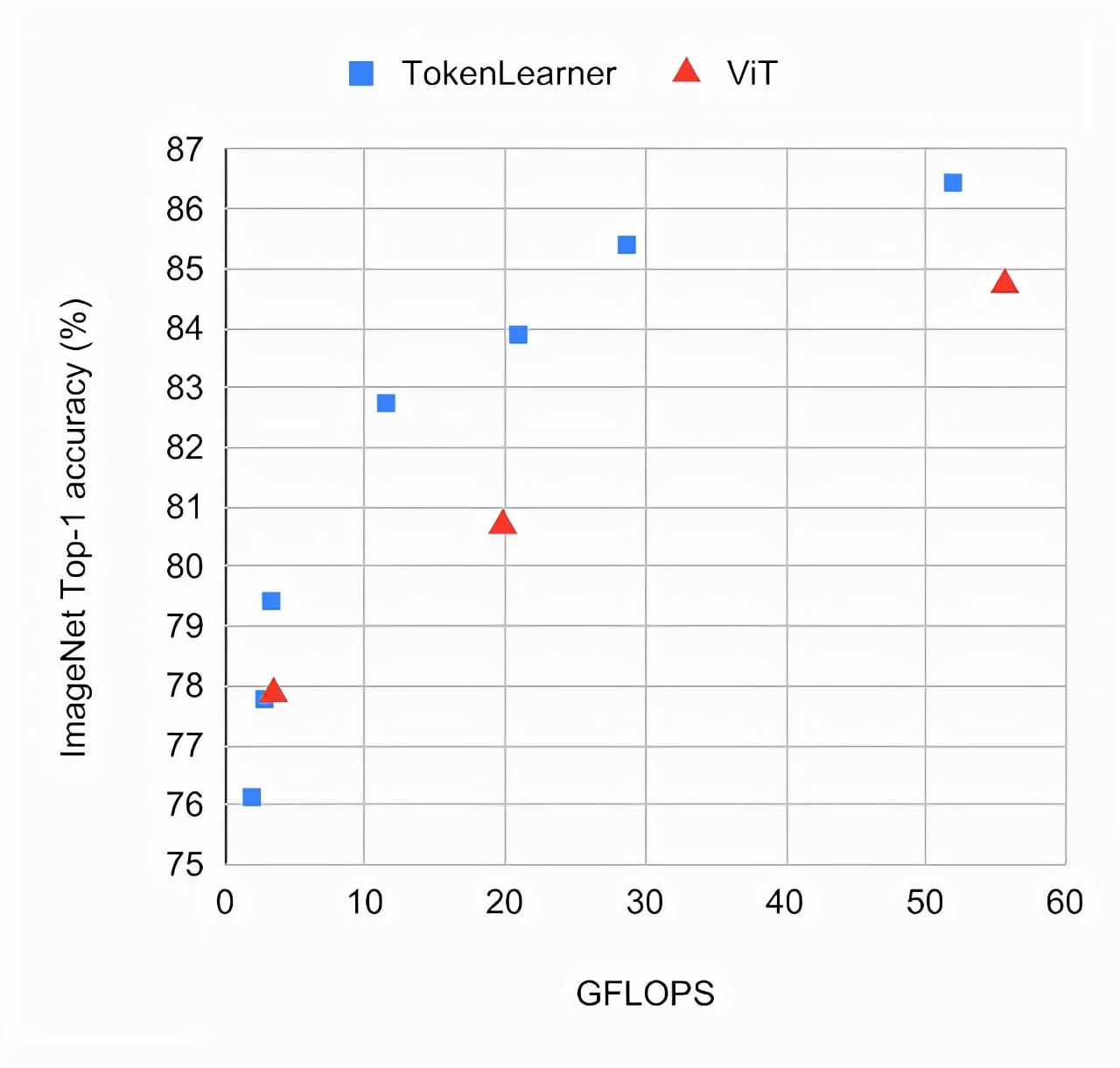
 对比实验将使用具有TokenLearner的ViT模型与标准ViT模型在ImageNet few-shot数据集上进行比较,并采用相同的设置。TokenLearner将会被放置在每个ViT模型的不同位置,例如网络的1/2和3/4处。模型是通过JFT 300M进行了预先训练。根据图表观察可知,TokenLearner模型在准确率和计算量方面的表现都优于ViT。在ImageNet分类任务上,不同版本的ViT模型表现出各自的优劣。在更大的ViT模型中,引入了TokenLearner,这个模型包含24个注意力层,并以10x10(或8x8)的patch作为初始token的L/10和L/8。在进行
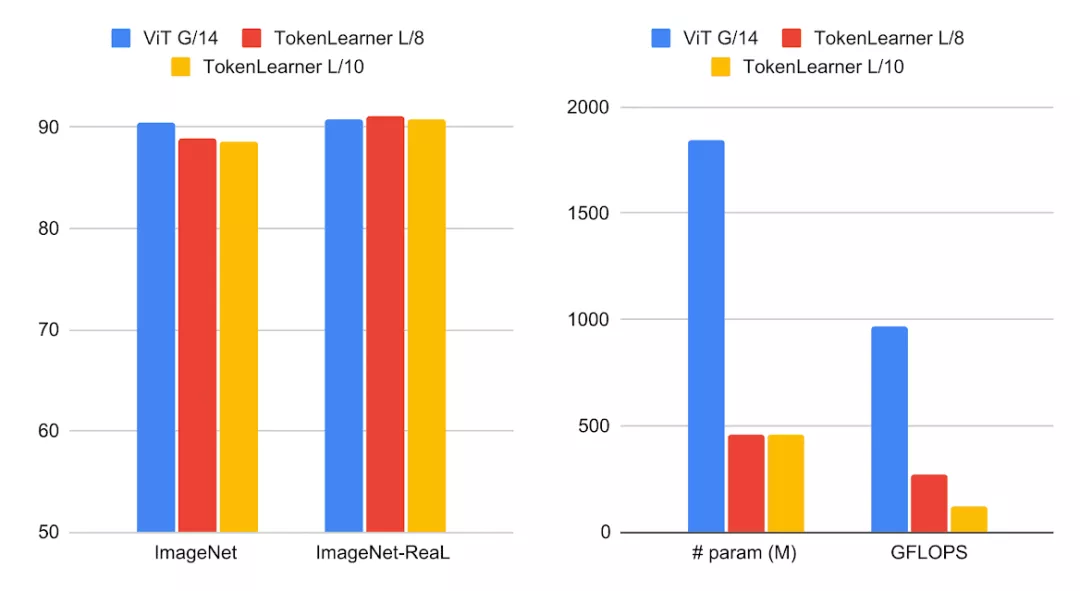
对比实验将使用具有TokenLearner的ViT模型与标准ViT模型在ImageNet few-shot数据集上进行比较,并采用相同的设置。TokenLearner将会被放置在每个ViT模型的不同位置,例如网络的1/2和3/4处。模型是通过JFT 300M进行了预先训练。根据图表观察可知,TokenLearner模型在准确率和计算量方面的表现都优于ViT。在ImageNet分类任务上,不同版本的ViT模型表现出各自的优劣。在更大的ViT模型中,引入了TokenLearner,这个模型包含24个注意力层,并以10x10(或8x8)的patch作为初始token的L/10和L/8。在进行之后,将这两个模型与48层的ViT G/14模型进行对比。可以观察到,TokenLearner在表现上与G/14模型相当,但仅需使用少量参数和计算量。
左边是大规模TokenLearner模型和ViT G/14在ImageNet数据集上分类准确度的比较;右边是参数量和FLOPS的对比
高性能视频模型 星空体育官方版
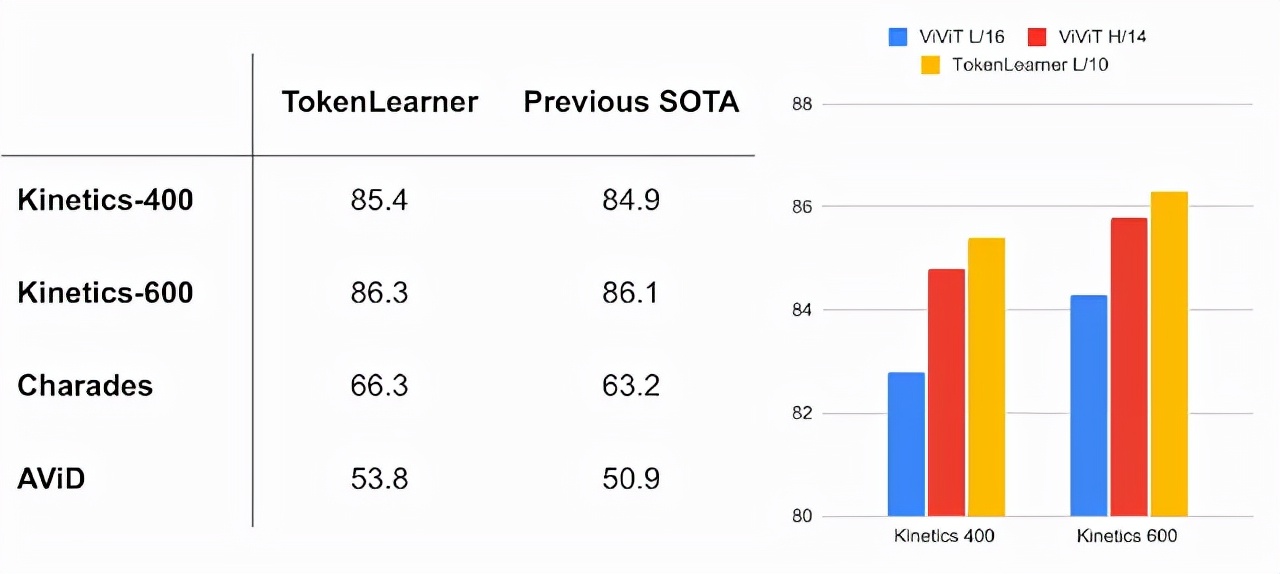
视频理解是计算机视觉的一个重要挑战,TokenLearner在多个视频分类数据集基准上取得了领先的性能。在Kinetics-400和Kinetics-600上的表现优于以前的Transformer模型,并且在Charades和AViD上也超越了先前的CNN模型。TokenLearner结合了视频视觉Transformer(ViViT),在每个时间段学习8(或16)个token。
左图显示了视频分类的任务,右图展示了不同模型的比较
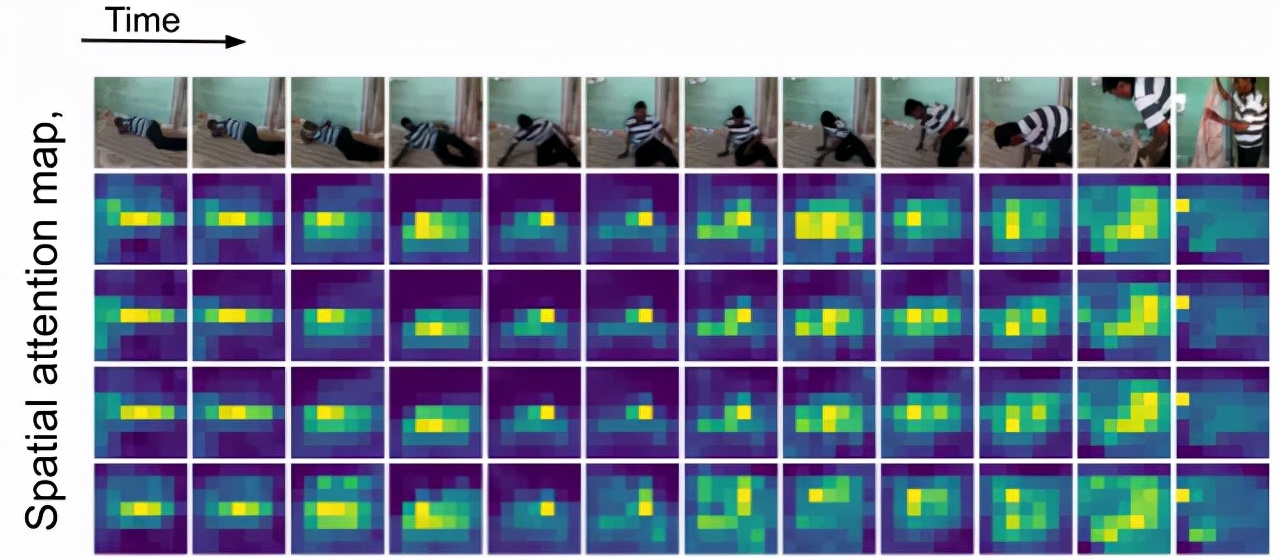
 随着时间的推移,在人物移动时,TokenLearner会注意到不同空间位置的变化,然后进行token化处理。TokenLearner的空间关注图的可视化揭示,在计算机视觉领域,虽然Vision Transformer是一个强大的模型,但使用大量token和高计算成本一直是将ViT应用于更大图像和更长视频时所面临的瓶颈。在这篇文章中作者指出,保留如此大量的token并在整个层级上进行完全处理是没有必要的。同时,作者还证实了通过学习一个基于输入图像的自适应提取标记的模块,可以在减少计算的同时获得更佳的表现。最终,在多个公共数据集上进行的验证也证实了TokenLearner在视频表征学习任务中的出色表现。
随着时间的推移,在人物移动时,TokenLearner会注意到不同空间位置的变化,然后进行token化处理。TokenLearner的空间关注图的可视化揭示,在计算机视觉领域,虽然Vision Transformer是一个强大的模型,但使用大量token和高计算成本一直是将ViT应用于更大图像和更长视频时所面临的瓶颈。在这篇文章中作者指出,保留如此大量的token并在整个层级上进行完全处理是没有必要的。同时,作者还证实了通过学习一个基于输入图像的自适应提取标记的模块,可以在减少计算的同时获得更佳的表现。最终,在多个公共数据集上进行的验证也证实了TokenLearner在视频表征学习任务中的出色表现。

星空体育手机版
星空体育网页版
星空体育入口
星空体育网站
星空体育官方 星空体育官方版
